孟德尔随机化诞生的背景
在传统的观察实验中,研究者通常只能观察被动的现象,而不能主动干预实验,从而会受到许多干扰因素的影响,带来不确定性,让得出的结论不可信。
而孟德尔随机化这种研究利用遗传的随机分配,将样本个体随机分为不同组,确保了研究样本在遗传特征上是随机的,避免了这种不可信。
假如威廉爵士研究金坷垃是否影响了植物的生长。上次实验中他在试验田里观察到了他的植物的氮磷钾吸收都增加了但是氮吸收只增长了一点点。所以这次他想观察植物的氮吸收是否真的受到了金坷垃的影响。如果他继续在田里观察他的植物,那么将受到许多因素的影响,降水,日照
本文是利用两样本孟德尔随机化方法探究血液中的代谢物(blood metabolites)与冠心病(coronary artery disease (CAD) )发病风险之间的因果关系。
血液中的代谢物可以反应个体的遗传组成并能预测或影响疾病的发生发展。
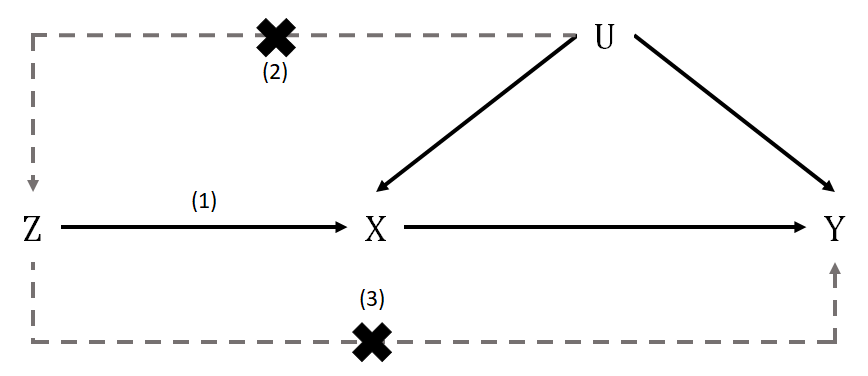
孟德尔随机化(MR)作为一种流行的遗传流行病学研究设计方法,它通过使用遗传变异作为工具变量,可以探究暴露和结局之间的因果关系。
Abstract
样本 :
公共数据库中的大规模的代谢组-全基因组关联分析数据和冠心病全基因组关联分析数据
我们对486种代谢物的遗传变异采用了统一的入选标准。选择 MR 分析中常用的较为宽松的阈值,即P< 1×10-5为显著的关联分析结果入选条件;在提取出每个代谢物对应的显著的SNP后,以千人基因组中欧洲人(EUR)基因型为参考模板,进行连锁不平衡分析,同时满足以下三个条件认为连锁不平衡并保留_P_值最小的SNP作为独立的遗传变异:(1)位于同个染色体;(2)相互距离在500 kb以内;(3)连锁不平衡参数*r*2>0.1。
因为处于同个代谢通路的代谢物可能会受到相似的遗传变异调控,即可能存在多个代谢物与同一个SNP显著相关,这将违反MR假设标准。因此,本研究采用限制性选取工具变量的方法,排除与两个以上代谢物均显著相关的SNP。同时排除已知的冠心病风险因素相关的SNP(包括身体质量指数、身高、腰围、臀围、腰臀比、血脂相关的SNP)。
方法 :
通过逆方差加权法和其他4种两样本孟德尔随机化模型来评估血液代谢物与冠心病之间的因果关系。使用异质性检验、基因多效性检验和敏感性分析来评估结果的稳定性和可靠性。
- inverse variance weighted (IVW) method, etc
- Heterogeneity, horizontal pleiotropy, and sensitivity tests
结果 :
486个代谢物中,共有32个代谢物与冠心病的因果关系效应值达到名义上显著(逆方差加权法,P < 0.05),其中包含11个已知代谢物和21个未知代谢物。
- 有3个已知代谢物在至少3种孟德尔随机化模型中达到统计学显著。但是利用 leave-one-out 法进行敏感性分析并剔除混杂的工具变量后(elimination of the confounding instrumental variables.),3个代谢物对应的因果效应不再具有统计学意义。
- nominally causative association
- N-乙酰鸟氨酸 N-acetylornithine, (Des-Arg9)-缓激肽 bradykinin-des-arg (9), and 丁二酰基肉碱succinylcarnitine
http://metabolomics. helmholtz-muenchen. de/gwas/.
专有名词
- Metabolome-based genome-wide association study (mGWAS)
- GWAS of CAD
